7月25日讯:近来诸多国产大模型异军突起,助力相关行业产业发展。北京知未智能科技有限公司日前在上海发布了知未智能 KDF 大模型 ,以及基于该模型研发的一系列产品,包括“ KDF 智讯”、“KDF 绝未”、“KDF 中书”等金融行业工具。
IT之家经过查询得知,知未智能 KDF 大模型的训练数据以中文为主,并包含大量的金融数据,以提升模型在商业和金融领域的问题处理能力。
此外,训练数据中还融合了部分英文与代码数据,以适应模型的通用能力。在训练过程中,知未智能 KDF 大模型将单个汉字视为独立的 Token 进行处理。模型参数量达 1400 亿,训练 Token 数达到 4000 亿。从代码量角度看,数据处理部分约 5000 行,模型实验部分约 2000 行,模型训练部分约 500 行。
在具体训练过程中,知未智能 KDF 大模型采用了基于 PyTorch 优化的 GELU 非线性激活函数。GELU 作为非线性激活函数,在各类任务中表现相对出色,有助于模型更精确地捕获复杂数据特征,确保整个开发、训练和部署过程的高效运行。
在网络结构方面,开发团队对模型进行了深度优化。与 LLaMA 模型相比,该模型在每一层使用更少的参数,有效降低计算需求和内存占用。同时,网络深度得到加强,使模型具备更强大的表示能力,能够学习到更为复杂的数据特征。
为提升模型在大规模数据处理中的可扩展性,开发团队重新调整了注意力层的 Bias,并引入了 Flash Attention 技术,旨在节省显存并提高模型训练和推理速度。得益于降低的计算量和内存需求,Flash Attention 使得知未智能 KDF 大模型在有限的硬件资源下实现更高效的运行。
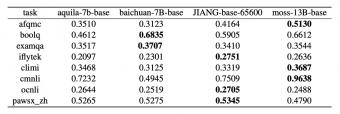
从部分基准测试结果来看,知未智能 KDF 大模型在七个自然语言处理任务中展现出稳定的性能。在某些任务上,如 iFlytek 和 CMNLI,知未智能 KDF 大模型表现相对出色,在 ExamQA 和 OCNLI 测试中,各模型的表现大致相同,凸显了该模型处理不同类型文本和领域知识方面的能力。

知未智能科技 CEO 段清华表示,现有通用大模型在具体行业应用性和中文能力方面的局限是知未智能选择从零训练知未智能 KDF 大模型的主要原因,Chatglm 在具体行业应用能力上相对薄弱,MOSS 采用英文模型为基底而对中文支持不足,LLaMA 训练数据大多为英文数据而中文能力相对较弱。了,因此研发团队选择从零开始训练知未智能 KDF 大模型,以便更好地提升其中文能力以及行业适用性。
在模型训练过程中,开发团队不断深入理解技术细节,力求打造一款“功能强大、性能优越”的中文模型,作为一款应用于金融和商业的垂直领域大模型,知未智能 KDF 大模型将持续推动公司产品的开发创新。
知未智能 KDF 大模型目前已于 Hugging Face 开源,未来将不限制商业使用
原标题:国产 1400 亿参数知未智能 KDF 大模型发布,聚焦金融和商业垂直领域