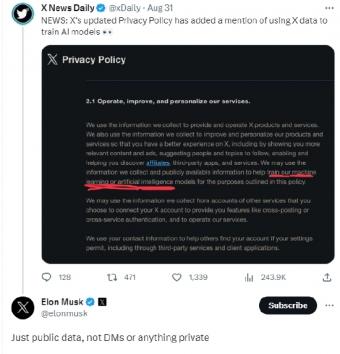
9月2日讯:据报道,埃隆・马斯克旗下社交平台 X(推特)日前调整了隐私政策,允许 X 使用用户发布的信息来训练其人工智能(AI)模型。
新的隐私政策将于 9 月 29 日生效。新政策规定,X 可能会使用所收集到的平台信息和公开可用的信息,来帮助训练 X 的机器学习或人工智能模型。
对此,马斯克在 X 上回应称,X 只会使用公开的信息来训其练人工智能模型,不会使用任何私有的内容。

今年 7 月,马斯克曾在一次音频直播中表示,他旗下的人工智能初创公司 xAI 将使用 X 平台上的公共数据来培训其人工智能模型。
目前尚不清楚,马斯克将如何使用来自 X 平台上的用户信息,以及用于哪些人工智能模型。
对此,X 尚未发表评论。
之前,马斯克一直反对其他平台使用 X 的数据来训练人工智能模型。今年 4 月,马斯克甚至威胁要起诉微软,称微软非法使用 X 的数据训练其人工智能模型。
今年 7 月,马斯克宣布成立人工智能公司 xAI,旨在使用人工智能来帮助理解宇宙的真实本质。而在此之前,马斯克曾警告称,人工智能可能摧毁人类文明。而且,他还签署了一封联名信,呼吁暂停训练比 OpenAI 的 GPT-4 更强大的人工智能系统。
xAI 并不是马斯克首次涉足人工智能领域,他还是 ChatGPT 开发商 OpenAI 的早期支持者,但于 2018 年离开了公司董事会。马斯克曾表示,他对 OpenAI 的成立至关重要,甚至连公司名称都是他想出来的。
知情人士称,当 ChatGPT 在去年 11 月首次亮相并迅速蹿红后,马斯克特别愤怒。自那以后,他一直对人工智能聊天机器人持批评态度。
为 ChatGPT 等生成式人工智能产品提供动力的技术,需要大量数据来训练。过去,这些数据都是从 Reddit 和维基百科等公开网站上获取的。
如今,这些公司(如 Reddit 和维基百科)想从这一点上获利,否则就停止提供数据。例如,Reddit 在 4 月份曾表示,计划向访问其数据的人工智能公司收取费用。此外,《纽约时报》和亚马逊等其他网站也在屏蔽 OpenAI 的网络爬虫。
众所周知,社交媒体网站拥有无穷无尽的用户生成内容,对于渴望获得新培训数据来源的人工智能公司来说,它们就是一座金矿。
Facebook 母公司 Meta 也在开发自己的生成式人工智能模型,最近推出了一个选项,让 Facebook 用户选择不分享他们的数据来训练其人工智能模型。
但有媒体报道称,Meta 的承诺是有局限性的,而且不能保证用户的所有信息都会从其人工智能训练数据库中删除。
原标题:X(推特)调整隐私政策,可拿用户发布的信息训练 AI 模型