商汤科技携手上海 AI 实验室、香港中文大学和复旦大学,正式发布新一代大语言模型 InternLM2,即书生・浦语 2.0。这一里程碑式的发布标志着语言模型领域的巨大突破,让我们一同揭开 InternLM2 的神秘面纱。
InternLM2:规模庞大,性能卓越
强大的训练基础
InternLM2 在 2.6 万亿 token 的语料上进行训练,为其提供了强大的语言学习基础。继承第一代书生・浦语的设定,InternLM2 不仅包含 7B 参数规格,还新增了 20B 参数规格,同时提供基座和对话等多个版本,保持了开源和商用免费授权。
高效的数据清洗过滤技术
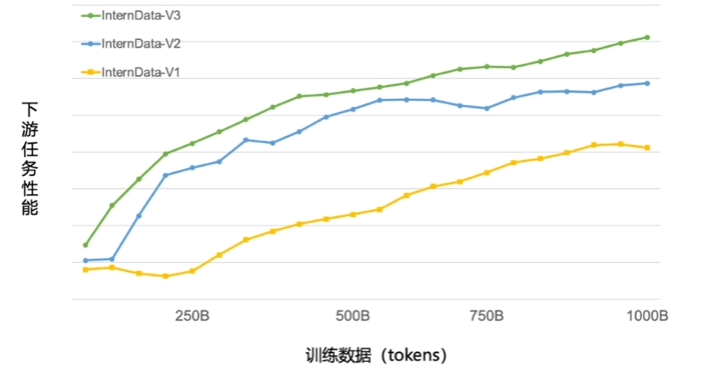
浦语背后的数据清洗过滤技术经历三轮迭代升级,仅使用约 60% 的训练数据即可达到使用第二代数据训练 1T tokens 的性能表现。这一技术的升级使得 InternLM2 在处理海量数据时更加高效。
强化的语言建模能力
与第一代 InternLM 相比,InternLM2 在大规模高质量验证语料上的 Loss 分布整体左移,显示其语言建模能力得到显著增强。这意味着 InternLM2 能够更准确地理解并生成复杂的语言结构。
改进的训练窗口和位置编码
InternLM2 通过拓展训练窗口大小和位置编码改进,支持 20 万 tokens 的上下文,能够一次性接受并处理约 30 万汉字的输入内容,相当于五六百页的文档。这一改进使得 InternLM2 在处理更长篇幅文本时表现出色。
性能对比:InternLM2 在中等规模上超越同类模型
下表对比了 InternLM2 各版本与 ChatGPT(GPT-3.5)以及 GPT-4 在典型评测集上的表现。在 20B 参数的中等规模上,InternLM2 整体表现接近 ChatGPT,展现出卓越的性能。
模型参数规模性能表现
InternLM2 7B7B优异
InternLM2 20B20B接近 ChatGPT
ChatGPTN/A作为对比基线,整体表现较优
GPT-4N/A作为对比基线,整体表现较优
InternLM2 的发布标志着大语言模型领域的技术飞跃,其庞大的训练基础和优越的性能表现使其在同类模型中脱颖而出。商汤科技为语言模型的未来注入了新的活力,InternLM2 势必引领大语言模型的新时代。期待这一强大模型在各个领域带来更为卓越的语言理解和生成能力。