
开源战在这半个月愈演愈烈。先是Llama 3.又到微软Phi-3.再到今天苹果发布的OpenELM。四种不同小参数版本全部上线,我们离iPhone装进大模型不远了。
从Llama 3到Phi-3.蹭着开源热乎劲儿,苹果也来搞事情了。
今天,苹果团队发布了OpenELM,包含了2.7亿、4.5亿、11亿和30亿四个参数版本。
与微软刚刚开源的Phi-3相同,OpenELM是一款专为终端设备而设计的小模型。

论文称,OpenELM使用了「分层缩放」策略,来有效分配Transformer模型每一层参数,从而提升准确率。
如下这张图,一目了然。
在约10亿参数规模下,OpenELM与OLMo相比,准确率提高了2.36%,同时需要的预训练token减少了2倍。

抱抱脸创始人表示,苹果加入了AI开源大战,一口气在HF中心发布了四款模型。
OpenELM有多强?
OpenELM的诞生,显然瞄准了谷歌、三星、微软这类的竞争对手。
近几天,微软开源的Phi-3.在AI社区引起了不小的反响。
因为,小模型的运行成本更低,而且针对手机和笔记本电脑等设备进行了优化。

根据论文介绍,苹果这款模型不仅能在笔记本(配备英特尔i9-13900KF CPU、RTX 4090 GPU,24GB内存),还可以在M2 MacBook Pro(64GiB内存)运行。
而OpenELM具体性能表现如何?
在零样本和少样本设置中,OpenELM的结果如下图表3所示。

通过与开源的大模型比较,OpenELM的变体比12亿参数OLMo的准确率提高了1.28%(表4a)、2.36%(表4b)和 1.72%(表4c)。
值得注意的是,OpenELM使用了OLMo少2倍的预训练数据的情况下,达到了这一水平。

再来看模型指令微调的结果。
如下表5所示,在不同的评估框架中,指令微调都能将OpenELM的平均准确率提高1-2%。

表6展示了参数高效微调的结果。PEFT方法可以应用于OpenELM,LoRA和DoRA在给定的CommonSense推理数据集中,提供了相似的平均准确度。

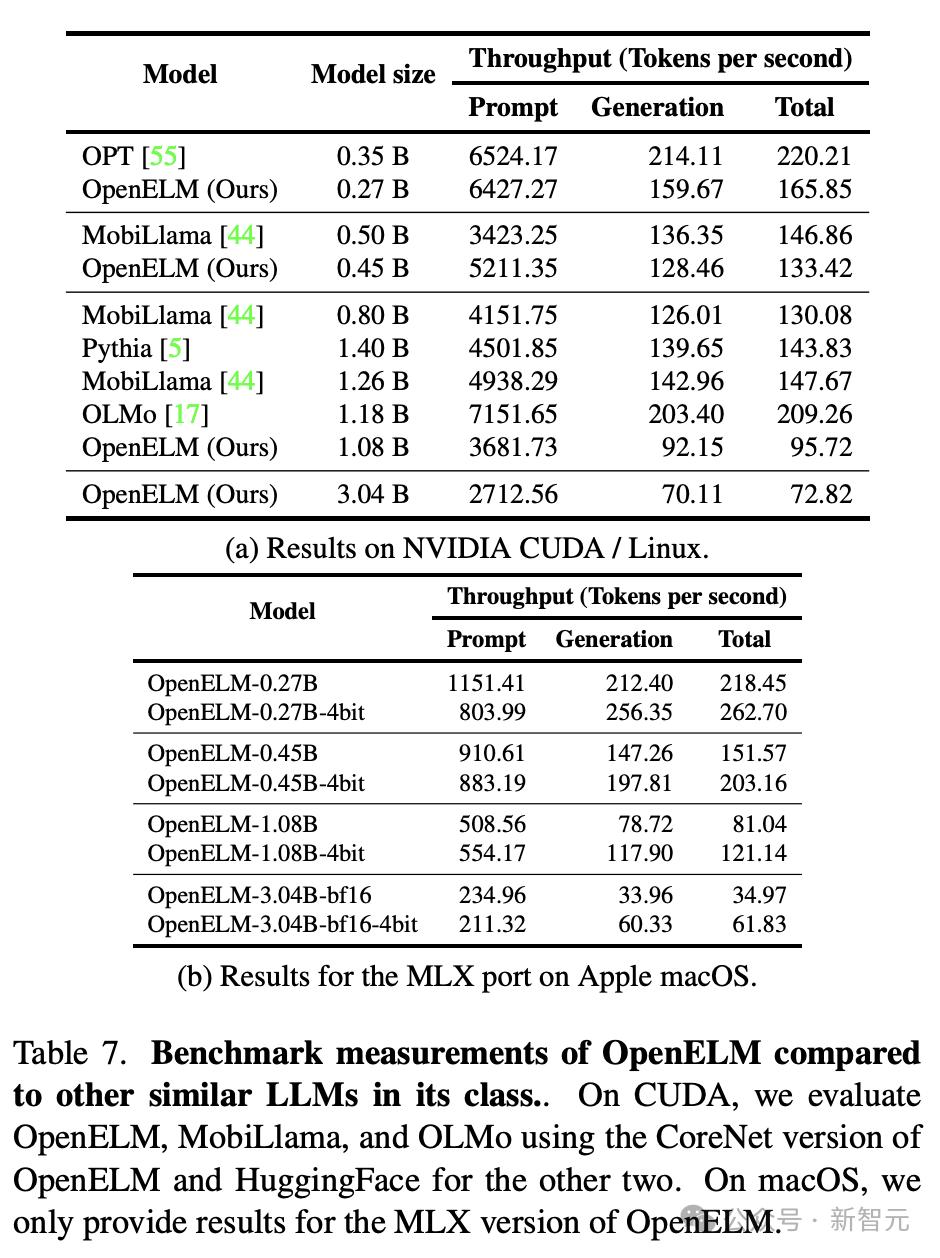
下表7a和7b分别显示了GPU和MacBook Pro上的基准测试结果。
尽管OpenELM对于相似的参数数量具有更高的精度,但研究人员观察到OpenELM要比OLMo慢。
虽然本研究的主要重点是可重复性而非推理性能,但研究人员还是进行了全面分析,以了解瓶颈所在。
分析结果表明,OpenELM处理时间的很大一部分,归因于研究者对RMSNorm的简单实现。
具体来说,简单的RMSNorm实现会导致许多单独的内核启动,每个内核处理一个小输入,而不是像LayerNorm那样启动一个融合的内核。
用Apex的RMSNorm替换简单的RMSNorm,结果发现OpenELM的吞吐量有了显著提高。
然而,与使用优化LayerNorm的模型相比,性能差距仍然很大,部分原因是:
(1)OpenELM有113个RMSNorm层,而OLMo只有33个LayerNorm层;
(2)Apex的RMSNorm没有针对小输入进行优化。

作者贡献
有趣的是,论文最后一部分还列出了每位作者,在这项研究中的具体贡献。
从预训练数据收集和工具、架构设计、模型训练,到评估套件和工具、HF集成、指令微调、参数高效微调,再到性能分析和MLX转换、代码审查,bug修改和维护全程都分工明确。
具体每人参与的内容,如下图所示。

